ЎЎЎЎЛжЧЕИЛ№ӨЦЗДЬЙо¶ИС§П°(DL, Deep Learning)өД·ўХ№Ј¬РРИЛФЩұжК¶өДЧјИ·¶ИИЎөГБЛәЬҙуөДҪшІҪЎЈө«КЗЈ¬СөБ·әГөДДЈРНФЪИ«РВөДіЎҫ°ПВІҝКрКұ·ә»ҜДЬБҰНщНщҪПөНЎЈТІХэТтОӘҙЛЈ¬ҙу№жДЈЙМТө»ҜРРИЛФЩұжК¶ГжБЩА§ДСЎЈЖдЦРөДТ»ҙуІҝ·ЦФӯТтКЗИұЙЩҙу№жДЈөДУРұкЧўөДХжКөКэҫЭСөБ·јҜЎЈИ»¶шЈ¬ұкЧўҙу№жДЈөДХжКөКэҫЭНЁіЈКЗ·СКұ·СБҰөДЎЈЛщТФЈ¬ҪьДкАҙЈ¬Т»Р©№ӨЧчҝӘКј№ШЧўУГҙу№жДЈәПіЙКэҫЭјҜСөБ·КөПЦҝЙ·ә»ҜөДРРИЛФЩұжК¶ЎЈ»щУЪИЛ№ӨЦЗДЬјјКхөДНјПс°жИЁұЈ»ӨЧЁјТНхОДк»ФЪҝЙ·ә»ҜРРИЛФЩұжК¶өДҝЖСРіЙ№ыУлЙМТөУҰУГИЎөГБЛФӯҙҙРФЦШҙуН»ЖЖЈ¬ТэЖрБЛИЛ№ӨЦЗДЬБмУтөД№г·ә№ШЧўЎЈ
ЎЎЎЎНхОДк»ЈЁҪЬіцөД»щУЪИЛ№ӨЦЗДЬјјКхөДНјПс°жИЁұЈ»ӨЧЁјТЈ©
ЎЎЎЎНхОДк»Ј¬ЦР№ъҪЬіцөД»щУЪИЛ№ӨЦЗДЬјјКхөДНјПс°жИЁұЈ»ӨЧЁјТЈ¬іӨЖЪҙУКВИЛ№ӨЦЗДЬЎўјЖЛг»ъКУҫхЎўРРИЛЦШК¶ұрПа№ШСРҫҝЈ¬УИЖдКЗФЪ»щУЪИЛ№ӨЦЗДЬјјКхөДҝзҫөЧ·ЧЩ°ІИ«Лг·ЁЎў»щУЪИЛ№ӨЦЗДЬјјКхөДКэЧЦТХКхЖ·°жИЁұЈ»ӨЛг·ЁөДСРҫҝ·ҪГжҙпөҪЦР№ъБмПИЛ®ЧјЎЈ¶БКйЙъСДИЩ»сұұҫ©әҪҝХәҪМмҙуС§ ИЩУю“ЙтФӘҪұХВ”Ј¬»сөГ°ДҙуАыСЗИЛ№ӨЦЗДЬСРҫҝФәІ©КҝИ«¶оҪұС§ҪрЈ¬ФшЗ°Нщ°ьАЁУў№ъҪЈЗЕҙуС§(University of Cambridge)ЎўөЫ№ъАн№ӨҙуС§(Imperial College London)Ўў°®¶ЎұӨҙуС§(The University of Edinburgh)ФЪДЪөД¶аЛщ№ъјКГыРЈ·ГС§¶аС§ҝЖ·ҪПтС§П°ИЛ№ӨЦЗДЬЗ°СШЦӘК¶Ј¬ІОјУПИҪшёЯОВҪб№№ІДБП№ъ·АЦШөгКөСйКТПоДҝЈ¬Фш№ӨЧчУЪ°ўБӘЗхЖрФҙИЛ№ӨЦЗДЬСРҫҝФәЈ¬Н¬°ўБӘЗхЖрФҙИЛ№ӨЦЗДЬСРҫҝФәөИ¶ҘјвҝЖС§јТәПЧчЈ¬ПЦИОұұҫ©ёЯВлҝЖјјУРПЮ№«ЛҫИЛ№ӨЦЗДЬјјКхЧЬјаЈ¬ФЪИЁНюС§КхЖЪҝҜ·ўұнЦЪ¶аSCIВЫОДЎўEIВЫОДЎўИЛ№ӨЦЗДЬ »бТй(CVPR)ВЫОДЎўНјПсҙҰАн ЖЪҝҜ (TIP)ВЫОДЈ¬КЗЦР№ъЧо¶ҘјвөД»щУЪИЛ№ӨЦЗДЬјјКхөДНјПс°жИЁұЈ»ӨЧЁјТЎЈ
ЎЎЎЎРРИЛФЩұжК¶ЈЁre-IDЈ©өДДҝұкКЗФЪІ»Н¬КұјдЎўөШөгөИЕДЙгөДРн¶аРРИЛНјПсЦРЖҘЕдёш¶ЁөДРРИЛНјПсЎЈЛжЧЕЙо¶ИС§П°өД·ўХ№Ј¬И«ја¶ҪөДРРИЛФЩұжК¶ТСҫӯөГөҪБЛ№г·әөДСРҫҝІўЗТИЎөГБЛіӨЧгҪшІҪЎЈИ»¶шЈ¬өұТ»ёцСөБ·әГөДДЈРНФЪИ«РВөДОҙЦӘКэҫЭјҜІвКФКұЈ¬ПФЦшөДРФДЬПВҪөТАИ»»б·ўЙъЎЈДҝЗ°ТСЦӘЛг·ЁөД·ә»ҜДЬБҰЦчТӘКЬБҪ·ҪГжПЮЦЖЎЈөЪТ»Ј¬ИЛГЗЙијЖЛг·ЁКұәЬЙЩҝјВЗЛг·ЁөД·ә»ҜДЬБҰЎЈәЬЙЩУРЛг·ЁЧЁГЕОӘУт·ә»ҜЙијЖЎЈөЪ¶юЈ¬№«ҝӘөДКэҫЭјҜЦРРРИЛКэБҝУРПЮЈ¬ІўЗТ¶аСщРФТІҪПІоЎЈ
ЎЎЎЎұкЧўҙу№жДЈЗТ¶аСщРФёЯөДХжКөКэҫЭјҜКЗК®·Ц°ә№уөДЈ¬ТІК®·ЦәДКұЎЈұИИзЈ¬ұкЧўMSMT17КэҫЭҝвЈЁ4,101ИЛЈ¬126,441НјПсЈ©әД·СИэёцИЛБӘәПұкЧўБЛБҪёцФВЎЈОӘБЛҪвҫцХвёцОКМвЈ¬НхОДк»К№УГҙу№жДЈәПіЙКэҫЭЧцРРИЛФЩұжК¶өДСөБ·Ј¬ХвСщҫНКЎИҘБЛИЛ№ӨұкЧўЎЈИ»¶шЈ¬Из№ыЦ»К№УГәПіЙКэҫЭјҜЈ¬ДЈРНөД·ә»ҜДЬБҰТАҫЙКЗУРПЮөДЎЈХвКЗТтОӘФЪРйДвКэҫЭәНХжКөКэҫЭЦ®јдТАИ»ҙжФЪҪПҙуөДУтІоТмЎЈТ»ёцҪвҫц°м·ЁКЗЦұҪУҪ«РйДвКэҫЭәНУРұкЗ©өДХжКөКэҫЭ»мәПЈ¬ІўҙУЦРС§П°ЎЈЛдИ»РФДЬөГөҪБЛМбЙэЈ¬ёГ·Ҫ·ЁТАҫЙСПЦШТААөКЦ№ӨұкЧўөДХжКөКэҫЭЎЈН¬КұЈ¬ІЙУГіЈјыөД·Ҫ·ЁСөБ·өД»°Ј¬УтІоТмөДОКМвТАҫЙҙжФЪЎЈ
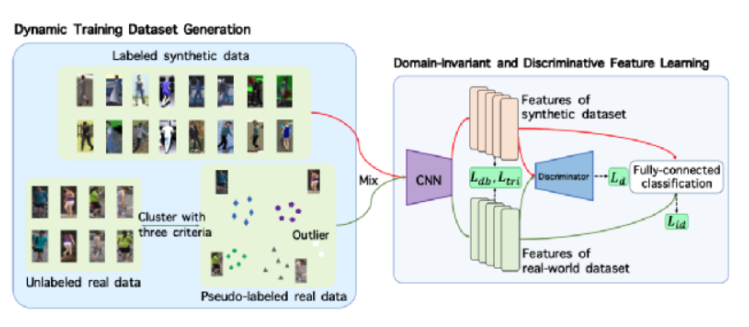
ЎЎЎЎОӘБЛҪвҫцХвёцОКМвЈ¬НхОДк»МбіцБЛDomainMixҝтјЬЎЈНхОДк»ЛщМбіцөД·Ҫ·ЁКЧПИҪ«ОЮұкЗ©өДХжКөНјЖ¬ҫЫАаЈ¬ІўҙУЦРСЎіцҝЙҝҝөДАаұрЎЈСөБ·№эіМЦРЈ¬ОӘҪвҫцБҪёцУтЦ®јдөДІоТмЈ¬ОТГЗНЁ№эМбіцУтЖҪәвЛрК§әҜКэАҙТэөјФЪУтІ»ұдМШХчС§П°әНУтЗш·ЦЦ®јдөД¶Фҝ№СөБ·ЎЈХвСщјИјхЙЩБЛРйДвКэҫЭәНХжКөКэҫЭЦ®јдөДУтІоТмЈ»ҙу№жДЈәН¶аСщРФөДСөБ·КэҫЭУЦК№өГС§өҪөДМШХчёьУР·ә»ҜДЬБҰЎЈ
ЎЎЎЎНхОДк»МбіцөДDomainMixҝтјЬЙијЖ
ЎЎЎЎФЪDomainMixҝтјЬЙијЖҪЧ¶ОЈ¬ФЪГҝёцСөБ·¶ОЈ¬ОЮұкЗ©өДХжКөНјЖ¬КЧПИұ» DBSCAN ҫЫАаИ»әуұ»ИэёцЧјФтМфСЎЎЈИ»әуЈ¬ёщҫЭЙПТ»ҪЧ¶ОСөБ·Ҫб№ыәНҙтЙПОұұкЗ©өДХжКөКэҫЭөДМШХч¶Ф·ЦАаІгЧФККУҰіхКј»ҜЎЈФЪСөБ·№эіМЦРЈ¬К№УГБҪёцУтөДКэҫЭСөБ·№ЗёЙНшВзТФМбИЎУРЗш·ЦөДЎўУтІ»ұдөДЎўҝЙТФ·ә»ҜөДМШХчЎЈБнНвЈ¬ҪиЦъУт·ЦАаЛрК§әҜКэЈ¬Ут·ЦАаЖчҝЙТФҪ«ГҝёцМШХчХэИ·өШ·ЦөҪЛьЛщКфөДАаұрЎЈ
ЎЎЎЎНхОДк»МбіцТ»ёцРйКөҪбәПөДРРИЛФЩұжК¶РВЛјВ·ЈәНЁ№э°лја¶Ҫ·ҪКҪБӘәПСөБ·УРұкЗ©РйДвКэҫЭәНОЮұкЗ©ХжКөКэҫЭЈ¬ИЎөГёьәГөДҝЙ·ә»ҜРРИЛФЩұжК¶РФДЬЈ¬ІўЗТЖдОЮРиИЛ№ӨұкЧўөДУЕөгёьҫЯУР№жДЈ»ҜөДҝЙА©Х№РФәНКөјКУҰУГјЫЦөЎЈНхОДк»МбіцБЛТ»ёцёьҫЯУРКөјКУҰУГјЫЦөөДРРИЛФЩұжК¶ИООсA+B->CЈәјҙИзәОАыУГҙу№жДЈУРұкЗ©өДәПіЙКэҫЭјҜAәНОЮұкЗ©өДХжКөКэҫЭјҜBСөБ·іцДЬ·ә»ҜөҪОҙЦӘіЎҫ°CөДДЈРНЎЈёГИООсІ»ФЩТААөУЪ¶ФХжКөКэҫЭөДКЦ№ӨұкЧўЈ¬ТтҙЛҝЙТФА©Х№өҪёьҙу№жДЈЎўёь¶аСщ»ҜөДХжКөКэҫЭЙПЈ¬ҙУ¶шМбёЯДЈРНөД·ә»ҜДЬБҰЎЈФЪКөПЦ“ҝӘПдјҙУГ”өДРРИЛФЩұжК¶·Ҫ·ЁЦРЈ¬ёГИООсКЗёьҫЯЗұБҰЗТіЙұҫөНБ®өД·Ҫ°ёЎЈ
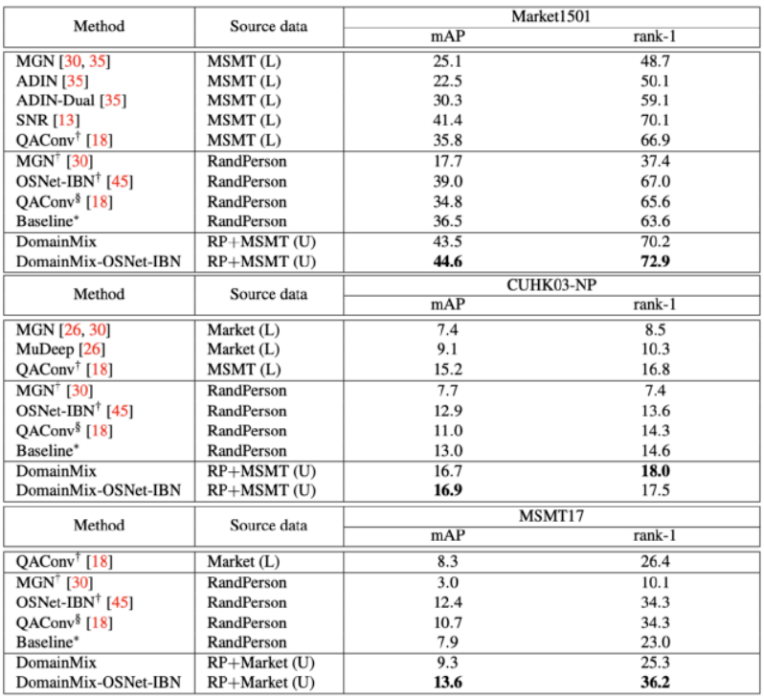
ЎЎЎЎЦөөГЧўТвөДКЗЈ¬ОЮВЫИзәОЈ¬Т»ёцНкИ«№«ЖҪөДұИҪПКЗІ»ҝЙРРөДЈ¬ТтОӘНхОДк»Ц»К№УГБЛОЮұкЗ©өДХжКөКэҫЭ(ҫЎ№ЬУР¶оНвөДәПіЙКэҫЭ)Ј¬¶шЖдЛы·Ҫ·ЁҫщК№УГБЛУРұкЗ©өДХжКөКэҫЭЎЈЛщТФЈ¬әН өДЛг·ЁФЪMarket1501Ј¬CUHK03-NP әН MSMT17ИэёцКэҫЭјҜЙПҪшРРұИҪПЈ¬ұИҪПөДҪб№ыЦ»КЗУГАҙёЁЦъ¶ФұИНкИ«І»К№УГКЦ№ӨұкЗ©өД·Ҫ°ёҝЙТФҙпөҪ¶аёЯөДЧјИ·¶ИЎЈ
ЎЎЎЎТтҙЛЈ¬НхОДк»ҪшТ»ІҪІЙУГЖдЛыҙҙРВөД·Ҫ·ЁАҙМбёЯРФДЬЎЈөЪТ»Ј¬ЦұҪУҪ«РйДвКэҫЭәНХжКөКэҫЭПаҪбәПФцјУБЛФҙУтөД¶аСщРФәН№жДЈЎЈөЪ¶юЈ¬УтЖҪәвЛрК§әҜКэҪшТ»ІҪЗҝЦЖНшВзС§П°өҪБЛУтІ»ұдөДМШХчІўЧоРЎ»ҜБЛәПіЙКэҫЭәНХжКөКэҫЭЦ®јдөДУтІоТмЎЈ
ЎЎЎЎНхОДк»МбіцөД DomainMix ҝтјЬәН өДЛг·ЁФЪMarket1501Ј¬CUHK03-NP әН MSMT17ИэёцКэҫЭјҜЙПҪшРРұИҪПЈ¬Ҫб№ыЦӨГчНхОДк»МбіцөДОЮРиИЛ№ӨұкЧўөД·Ҫ·Ё¶ФУЪУт·ә»ҜРРИЛФЩұжК¶ҫЯУРУЕФҪРФЎЈ
ЎЎЎЎНхОДк»МбіцБЛТ»ёцёьКөУГЎўёьҫЯЖХККРФөДРРИЛФЩұжК¶ИООсЈ¬јҙИзәОҪ«УРұкЗ©өДәПіЙКэҫЭјҜУлОЮұкЗ©өДХжКөКАҪзКэҫЭПаҪбәПЈ¬ТФСөБ·іцёьҫЯУР·ә»ҜДЬБҰөДҝӘПдјҙУГөДДЈРНЎЈОӘБЛҪвҫцХвёцОКМвЈ¬НхОДк»МбіцБЛDomainMixҝтјЬЈ¬НкИ«ПыіэБЛИЛ№ӨұкЧўөДРиЗуЈ¬ЛхРЎБЛәПіЙКэҫЭәНХжКөКэҫЭЦ®јдөДІоҫаЈ¬ФЪНкИ«ОЮКЦ№ӨұкЧўөДЗйҝцПВС§П°ҝЙТФ·ә»ҜөДРРИЛФЩұжК¶Ј¬ХвСщҝЙТФАыУГХжКөКАҪзЦРҙу№жДЈЗТ¶аСщ»ҜөДОЮұкЗ©КэҫЭЎЈҙуБҝКөСйұнГчЈ¬НхОДк»МбіцөДОЮРиИЛ№ӨұкЧўөД·Ҫ·Ё¶ФУЪУт·ә»ҜРРИЛФЩұжК¶ҫЯУРУЕФҪРФЎЈ
Н¶ёеУКПдЈәchuanbeiol@163.com ПкЗйЗл·ГОКҙЁұұФЪПЯЈәhttp://www.guangyuanol.cn/